This data version was released on 10/3/2023.
Welcome to our October 2023 release notes! We’re rolling out some exciting updates with this release.
Here are some of the key highlights:
- Automatically enrich your Salesforce with our new Salesforce Integration.
- Get up-to-date information on a unique IP with our IP Enrichment API.
- We now have 51 million company records in our Company Dataset.
- Our highest ever number of
experienceupdates (370M+) in the Resume Dataset. - Easily import our data to your warehouse with our [Beta] Data License Delivery as a Table format.
- Learn about a company’s fundraising history with our new [Beta] Funding Data Fields.
📣 Key Announcements
Schema Changes
display_name (Company Schema)
We are adding a free new
display_name field to the base Company dataset. It will appear in all Company responses going forward.
This field preserves the capitalization of the company name (unlike the name field which is lowercase). The display_name is set using the company’s self-reported name, so it should be accurate even for companies with non-standard capitalization (such as VMware, FedEx, or Dell EMC).
Use this field to display properly capitalized company names in a UI or other customer-facing project or product.
[BETA] Data License Delivery as a Table
In this release, we are launching a beta option to send License Delivery data in a relational table structure. It can be delivered directly to you or to any warehouse to upload. If you use an ETL (Extract, Transform, Load) process to ingest our Data License delivery, want to run SQL queries against the data, or use data warehouses like Snowflake and Databricks, this new format will save you time and effort. For more information or to join the beta, speak with your Customer Success Representative.❗Breaking Changes
Person ID Maximum Length Increase
⚠️ Upcoming Breaking Changes
⚠️ Person Changelog Restructure
Change Expected In: v25 / January 2024 We are rebuilding our changelog to include only the most relevant information. The Person changelog will no longer contain every record in our dataset, instead it will only contain IDs with changes. Additionally, the categories of changes in the Person changelog going forward will be limited to:- merged
- added
- opted-out
- deleted
- updated
⚠️ Snowflake Schema Standardization
Change Expected In: v26.1 / May 2024Update: Change Now Expected May 2024We originally planned this change for v25. We have decided to postpone it to v26.1. If you have any questions or concerns about this, please reach out to your Customer Success Manager.
- Make a copy of your current data after your April 2024 delivery. This way you not only have a backup, but can also compare new to old after you switch over.
- Go through the new standard schemas, which will be available by January 31.
- Prepare any script changes to your existing processes before the switch in May 2024.
⚠️ Company Insights Logic Changes
Change Expected In: v25 / January 2024 Effective January 2024, we are changing our Company Insights aggregation logic and filter parameters. As a result, the current employee count should be equal across the following fields going forward: We are also adding new“other_uncategorized” subfields which show the number of profiles for which there is not sufficient location or experience data to be counted in the corresponding aggregation in each field in order to reflect this parity.
Today, and up to v24.2, the API responses look like:
JSON
JSON
⚠️ Remove Oxford Comma from Industry Canonical Values
Change Expected In: v25 / January 2024 The Canonical Industries “leisure, travel & tourism” and “glass, ceramics & concrete” will be represented across all industry fields without Oxford commas. Currently, certain industry fields may erroneously include an Oxford comma for these values (ex: “leisure, travel, & tourism”). This change will affect the following fields:⚠️ Rename person.gender to person.sex
Change Expected In: v26 / April 2024
We are renaming the gender field to sex in the Person Schema. The output will remain the same.
✨ New Products and Features
Salesforce Integration
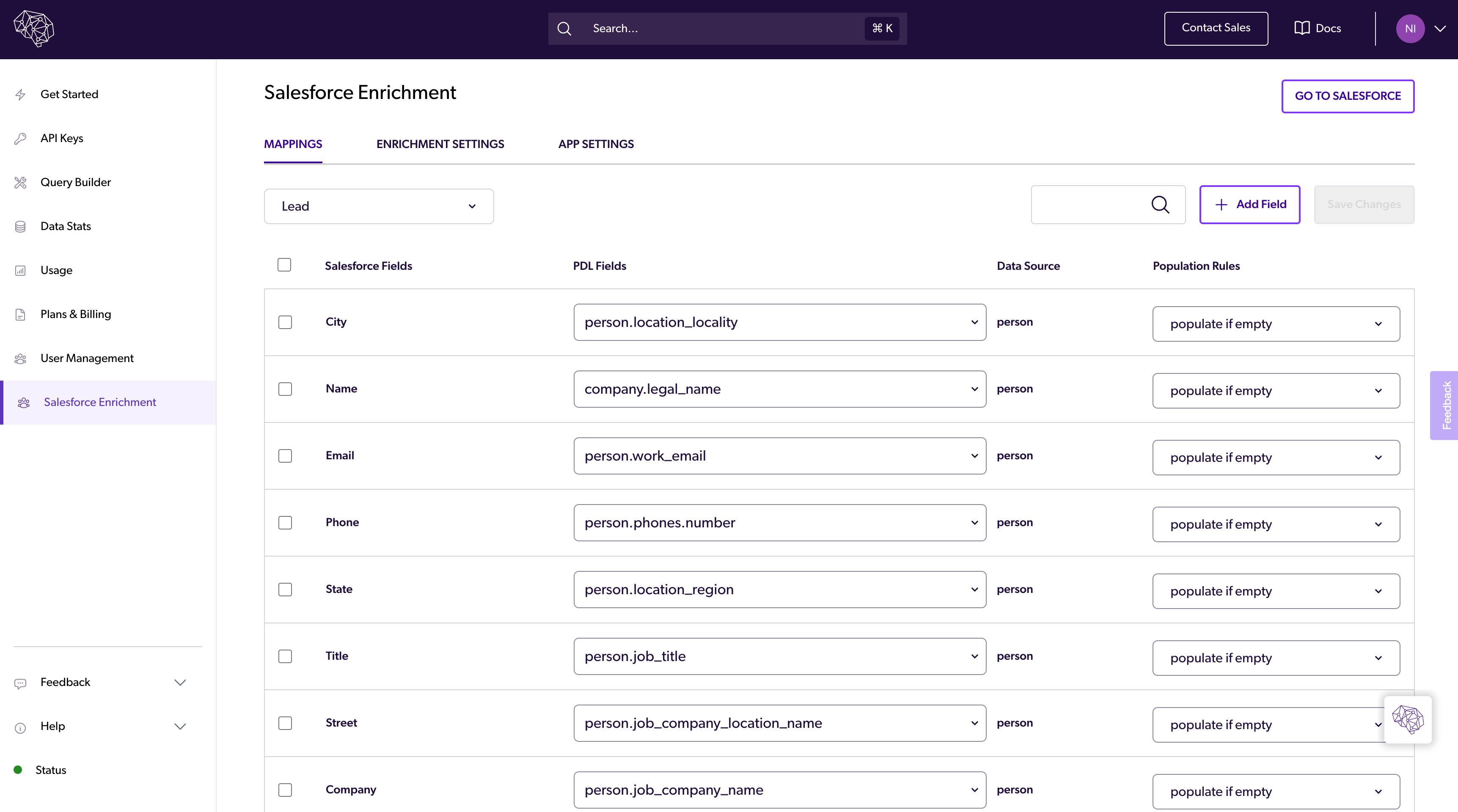
IP Enrichment API Full Release
Last quarter (v23), we released the Beta of the IP Enrichment API. In v24, we’re excited to roll out this API for General Availability! The IP Enrichment API provides a one-to-one IP match, giving you up-to-date information on a unique IP. With it, you can link website visitor IPs with company information, enable personalized web experiences, create target lists, identify website traffic sources, and more. Our coverage is continuing to grow rapidly. We have over 695M Individual Observed IPs and over 502k ASNs (Autonomous System Number blocks) in our dataset.Open-Source Rust SDK
Our new Rust SDK is an open-source SDK that lets you write Rust code to make HTTP requests to our APIs from your Rust application. For more information, check out our GitHub at https://github.com/peopledatalabs/peopledatalabs-rust. You can also submit pull requests, feature suggestions, and bug reports.ETA] F Funding Data Fields
We’re launching a closed beta for funding data ahead of the full rollout in early 2024. Funding information is the current #1 most upvoted feature on PDL’s Canny Feature Request board. We hear you! The beta will include 10 new Company fields providing information on a company’s fundraising history, including the amount of money raised, the number of funding rounds (i.e., Series B stage), and details on the specifics of the individual funding rounds. Reach out to your Customer Success Representative if you’d like to join the beta!🚀 Data Updates
Freshness
This quarter, we updated millions of jobs and locations in our Global Resume Dataset. See below for details:Coverage (Full Stats: Person, Company)
Resume Dataset
API Dataset
Email Dataset
Company Dataset
Commentary
- We now have over 51 million total company records in our Company Dataset, an increase of 71.87%
- Company identifying information linkages nearly doubled
- This quarter, there were significant increases to
experiencelinkages within our Resume Dataset- Most notably, we saw high growth for experience dates:
job_start_datelinkages grew by 60Mexperience.start_datelinkages grew by 47Mexperience.end_datelinkages grew by 36M- This growth was reflected across our datasets
- We also saw high increases in user-reported summaries:
job_summarylinkages increased by 29%experience.summarylinkages increased by 14%
experience.titlelinkages increased by 15M- Linkages for company identifying information associated with the
experienceobject also grew by 30M
- Most notably, we saw high growth for experience dates:
educationlinkages grew by 50M in our Resume Dataset
🛠 Improvements and Bug Fixes
Improvements
- Improved “name-only” matching performance for better prioritization of larger companies and fast-growing start-ups in our Company Enrichment API.
- Removed non-names (ex: “named”, “undefined”, “view”) from first and last name fields.
- Accreditations and degrees (ex: “b.eng”, “b.comm”, “b.eng-chemical”) no longer appear as first names.
- Improved canonicalization/matching for companies that end in “s”.
- Previously, the “s” at the end of company names would be dropped, in some instances leading to incorrect canonicalization x: Apples > Apple]. .
- Cleaned up “Manager” job level tags.
- These Manager tags were associated with roles such as Project Manager or Customer Relationship Manager - not titles we link to Manager in a practical sense.
- Improved Parent/Subsidiary linkages.
- Google and Waymo now correctly appear as subsidiaries of Alphabet.
- Removed incorrect parent/subsidiary links reported by users (ex: from Microsoft <> Emeraldx and Emeraldx <> Onex).
Bug Fixes
- Fixed instances of incorrect company locations.
- As an example, “.de” domains were assigned a headquarters of Delaware, US, rather than the correct location of Germany.
- Removed incorrect associations between Wells Fargo employees and Fargo, North Dakota location.
- Ph.D degrees were incorrectly associated with a Philosophy major.
- Cleaned up leftover examples of the “Saintckholm” (Stockholm), Sweden location cleaning error.
- Fixed unexpected matching behavior when querying Google.
- Previously, querying with criteria of name=”google” and location=”mountain view” incorrectly enriched to Google Japan.